

This article aims to provide a comprehensive understanding of stochastic gradient descent (SGD) in the context of optimization algorithms for machine learning. It will explain the mechanics of SGD, discuss its advantages and disadvantages, explore variants of SGD, and provide practical considerations for applying SGD in real-world scenarios. By the end of the article, you will have gained insights into the role of SGD in training machine learning models and its significance in optimization.
Gradient Descent
Gradient descent is a widely-used optimization algorithm employed in machine learning for minimizing loss functions. It operates by iteratively updating the parameters of a model in the direction of the steepest descent of the loss function for those parameters. In other words, it seeks to find the local minimum of the loss function by adjusting the model parameters in small increments.
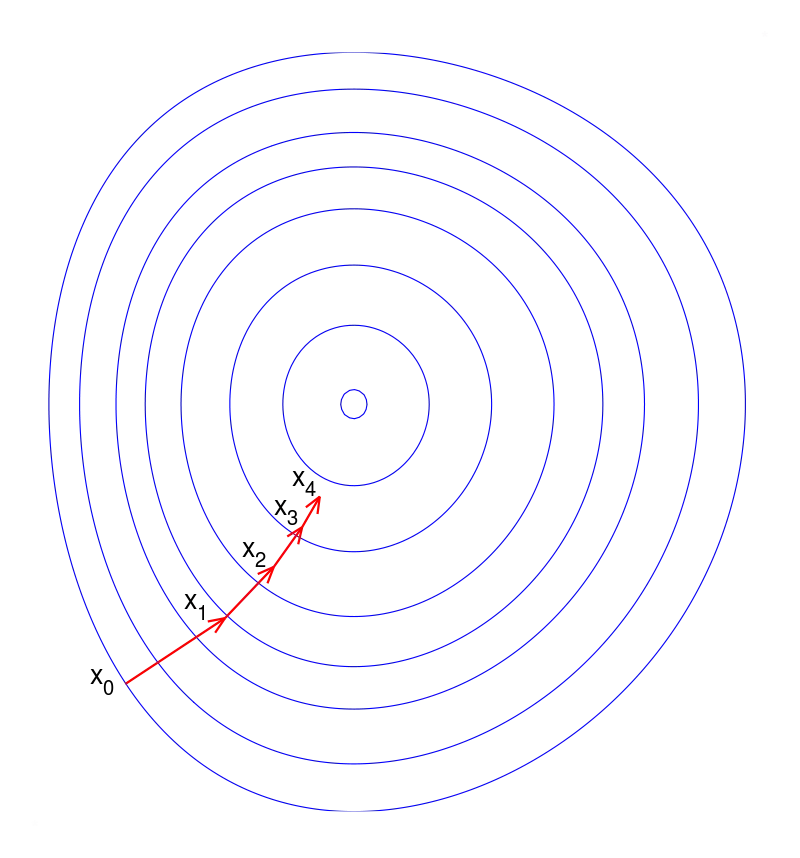
The gradient descent process can be visualized as descending a curved surface, where the objective is to reach the lowest point (minimum) of the surface. At each iteration, the algorithm computes the gradient of the loss function with respect to the parameters, which indicates the direction of the steepest increase. The parameters are then adjusted in the opposite direction of the gradient, effectively moving closer to the minimum of the loss function. This process is repeated iteratively until convergence, where further adjustments to the parameters result in negligible improvements in the loss function value.
Stochastic Gradient Descent
Stochastic gradient descent (SGD) is an optimization algorithm widely used in machine learning for minimizing loss functions and training models. Unlike traditional gradient descent, which updates model parameters using the average gradient computed over the entire dataset, SGD processes individual data samples or small batches of data during each iteration. This stochastic nature introduces randomness into the optimization process and allows SGD to handle large datasets more efficiently.
In SGD, rather than computing the gradient of the loss function for the parameters using the entire dataset, a single data sample or a small batch of data is randomly selected at each iteration. The gradient is then computed based on this subset of data, and the model parameters are updated accordingly. This approach introduces noise into the optimization process but enables faster convergence and better scalability, particularly for large datasets.
Trade-offs between Stochastic Gradients and Full Gradients
Using stochastic gradients in optimization offers several advantages, such as faster convergence, better scalability to large datasets, and the ability to escape local minima. However, the noisy nature of stochastic gradients can lead to fluctuations in the optimization trajectory and potentially hinder convergence to the global minimum. In contrast, full gradients provide a more accurate estimate of the true gradient but can be computationally expensive and memory-intensive, especially for large datasets. Therefore, the choice between stochastic gradients and full gradients involves trade-offs between convergence speed, computational efficiency, and optimization stability, depending on the specific characteristics of the dataset and the optimization task at hand.
Advantages and Disadvantages of SGD
Stochastic Gradient Descent offers several advantages over traditional gradient descent methods. One significant advantage is its faster convergence rate, particularly when dealing with large datasets. By computing gradients based on individual data samples or small batches, SGD updates model parameters more frequently, leading to quicker progress towards the optimal solution. Additionally, SGD requires lower computational resources compared to full-batch methods, making it suitable for training deep learning models on large-scale datasets with limited hardware resources.
Despite its advantages, SGD comes with certain drawbacks that must be considered. One notable drawback is the increased variance introduced by using stochastic gradients. Since SGD computes gradients based on subsets of the data, the updates to the model parameters can exhibit higher variability, leading to fluctuations in the optimization trajectory. This variance may result in less stable convergence behavior and make it challenging to determine when the optimization process has reached the optimal solution. Moreover, SGD’s reliance on noisy gradients can potentially cause oscillations in the optimization trajectories, especially in the presence of high learning rates or poorly chosen hyperparameters. Therefore, while SGD offers faster convergence and reduced computational requirements, practitioners must carefully tune its parameters and monitor its behavior to ensure effective optimization outcomes.
Selecting Learning Rates and Batch Sizes
Choosing the right learning rate and batch size is crucial for the success of Stochastic Gradient Descent (SGD). The learning rate determines the size of the step taken during parameter updates, while the batch size determines the number of data samples used to compute each gradient update. A learning rate that is too high can lead to oscillations or divergence in the optimization process, while a learning rate that is too low may result in slow convergence. Similarly, a small batch size can introduce more noise into the optimization process but may lead to faster updates, while a larger batch size can provide more accurate gradients but may slow down convergence and require more memory. Finding the optimal balance between learning rate and batch size often requires experimentation and tuning based on the specific characteristics of the dataset and model architecture.
Tuning Hyperparameters and Optimizing the SGD Training Process
In addition to learning rates and batch sizes, other hyperparameters such as momentum, regularization strength, and initialization schemes also play important roles in the performance of SGD. Momentum helps accelerate convergence by smoothing out fluctuations in the optimization trajectory, while regularization techniques such as L1 and L2 regularization can prevent overfitting and improve generalization performance. Furthermore, careful initialization of model parameters can significantly impact the optimization process and final model performance. Experimenting with different hyperparameter configurations and optimization strategies, coupled with rigorous validation techniques, is essential for optimizing the SGD training process and achieving optimal model performance.
Conclusion
Stochastic Gradient Descent is a powerful optimization algorithm widely used in training machine learning models. Its stochastic nature, where gradients are computed based on individual data samples or small batches, offers advantages such as faster convergence and reduced computational requirements. However, SGD also comes with challenges such as increased variance and the need for careful hyperparameter tuning. By understanding the mechanics of SGD and considering practical considerations like learning rates, batch sizes, and hyperparameter tuning strategies, practitioners can effectively leverage SGD to train efficient and effective machine learning models.