

In the world of natural language processing (NLP), BERT (Bidirectional Encoder Representations from Transformers) has dramatically improved the way we handle text understanding tasks, especially text classification. If you’ve been wondering “how does BERT work for text classification?”, this detailed guide will walk you through everything you need to know.
We’ll cover the fundamentals of BERT, how it processes text, and how it powers classification tasks with unprecedented accuracy.
Let’s dive right in.
What Is BERT?
BERT is a deep learning model developed by Google in 2018. It’s based on the Transformer architecture, but its unique innovation is being bidirectional, meaning it considers both the left and right context of a word simultaneously.
Traditional models like Word2Vec and GloVe are context-free (“bank” has the same embedding in “river bank” and “money bank”), but BERT is contextual, dynamically adjusting word meaning based on surrounding text.
BERT was pre-trained on massive datasets, such as Wikipedia and BooksCorpus, using two objectives:
- Masked Language Modeling (MLM): Predict randomly masked words.
- Next Sentence Prediction (NSP): Predict whether one sentence logically follows another.
These two tasks enabled BERT to deeply understand syntax, grammar, relationships, and semantics.
Why Use BERT for Text Classification?
Text classification requires understanding both:
- Local word meanings
- Global sentence structure
BERT excels at both, making it ideal for:
- Sentiment analysis
- Spam detection
- Topic classification
- Question-answer pair classification
- Intent recognition in chatbots
Key advantages:
- State-of-the-art accuracy
- Minimal feature engineering
- Fast fine-tuning for specific tasks
How BERT Works for Text Classification: Step-by-Step
Understanding how BERT powers text classification involves examining each component that contributes to its state-of-the-art performance. Let’s dive deeply into the process.
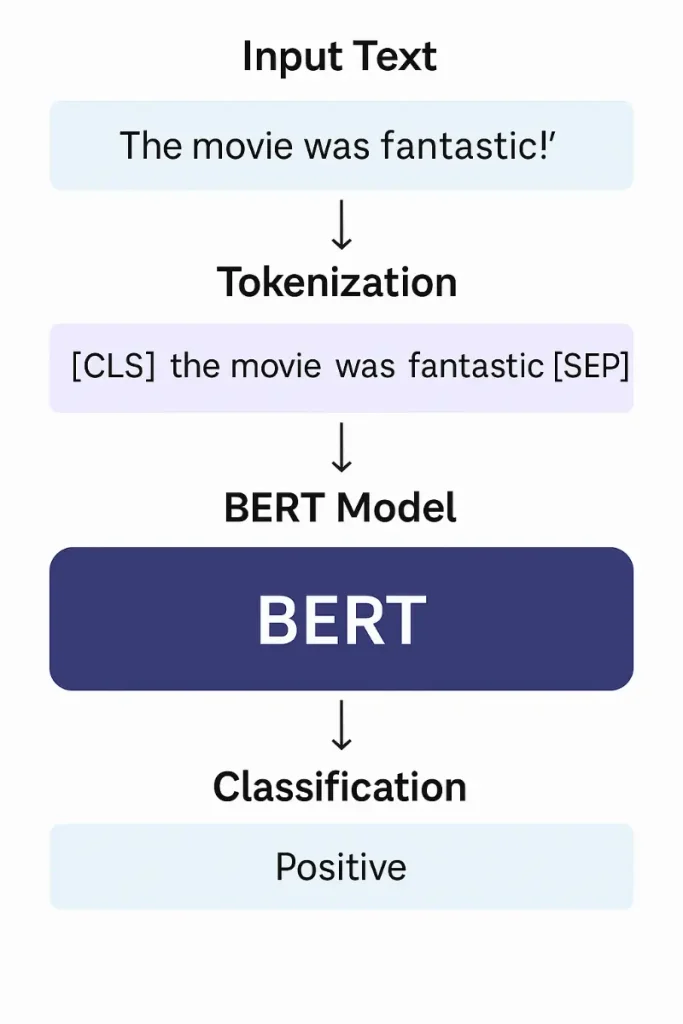
Step 1: Input Representation
Before feeding data into BERT, the text input needs to be formatted properly. BERT expects a specific structure:
- A special classification token [CLS] is added at the beginning of the sequence.
- A [SEP] token separates two sentences (useful for sentence-pair tasks).
- Each token is mapped to three embeddings:
- Token Embedding: Represents the token itself.
- Segment Embedding: Distinguishes between different sentences.
- Position Embedding: Encodes the position of the token in the sequence.
Example:
[CLS] The movie was fantastic! [SEP]
Each tokenized word, including [CLS] and [SEP], is transformed into vectors and summed together to form a complete input.
Step 2: Embedding Layer
BERT’s embedding layer combines the above embeddings:
- Token Embedding brings in the word-specific meaning.
- Segment Embedding distinguishes Sentence A and Sentence B (only needed in specific tasks).
- Position Embedding adds a sense of word order, critical for understanding syntax.
These embeddings are added element-wise and passed as input to the encoder.
Step 3: Encoding with Transformer Layers
BERT uses multiple layers of Transformer encoders. Each layer contains:
- Multi-Head Self-Attention Mechanism: Helps BERT focus on different parts of the sentence simultaneously.
- Feed-Forward Neural Network: Applies non-linear transformations to the attention output.
Self-attention enables each token to attend to every other token, giving BERT a complete bidirectional understanding of the text.
Each of these layers enriches the token representations with more context, gradually building sophisticated, nuanced embeddings.
Step 4: Extracting the [CLS] Token Representation
After passing through the Transformer layers, BERT outputs a contextualized embedding for each token.
The embedding corresponding to the [CLS] token is special:
- It is designed to aggregate information from the entire input sequence.
- It acts as a compressed representation of the input text.
Thus, it becomes a natural choice for classification tasks.
Step 5: Adding the Classification Head
The next step is to add a simple neural network on top of the [CLS] output:
- A dense (fully connected) layer takes the [CLS] embedding.
- A softmax activation function converts logits into probabilities.
Example in PyTorch:
import torch
import torch.nn as nn
class BERTClassifier(nn.Module):
def __init__(self, bert, num_classes):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dropout = nn.Dropout(0.3)
self.fc = nn.Linear(bert.config.hidden_size, num_classes)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
cls_output = outputs.last_hidden_state[:, 0, :]
cls_output = self.dropout(cls_output)
logits = self.fc(cls_output)
return logits
Adding dropout before the final layer improves generalization and reduces overfitting.
Step 6: Fine-Tuning the Whole Model
Unlike training from scratch, fine-tuning means:
- Starting with BERT’s pre-trained weights.
- Slightly adjusting them during supervised training.
Both the BERT backbone and the classification head are trained together.
Training typically involves:
- Cross-entropy loss for classification tasks.
- AdamW optimizer.
- A small learning rate (e.g., 2e-5).
- Training for 2-4 epochs.
Fine-tuning ensures BERT adapts specifically to the nuances of the target classification task.
Step 7: Making Predictions
Once fine-tuned, making predictions is straightforward:
- Tokenize the input text.
- Feed the input through the model.
- Apply softmax to obtain probabilities.
- Choose the class with the highest probability.
Example:
predicted_class = torch.argmax(logits, dim=1)
This predicted class corresponds to the label in your classification task (e.g., positive/negative sentiment).
Additional Considerations: Attention Masks and Padding
When batching inputs of varying lengths:
- Use attention masks to tell BERT which tokens are padding and should be ignored.
- Proper padding ensures that the model doesn’t attend to meaningless spaces.
This further boosts training efficiency and ensures that model focus remains on real content.
Practical Example: Sentiment Classification with BERT
Let’s walk through a simple real-world pipeline.
Install Required Libraries
pip install transformers
pip install torch
Load Pre-trained BERT
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
Prepare Input
inputs = tokenizer("I love this movie!", return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted = torch.argmax(logits, dim=1)
print(predicted)
If predicted is 1 (positive sentiment), our model thinks the review is positive!
Tips for Using BERT for Text Classification
- Use GPU: BERT is heavy. Always use a GPU-enabled machine if possible.
- Batch Size: Start with a small batch size (16 or 32) and adjust.
- Learning Rate Schedules: Use warmup strategies to avoid early training instability.
- Data Augmentation: Consider augmenting small datasets with backtranslation or synonym replacement.
- Layer Freezing: Initially freeze lower BERT layers and only fine-tune top layers for faster convergence.
Variants of BERT for Text Classification
Several optimized versions of BERT are available:
- DistilBERT: Smaller, faster, cheaper (95% of BERT’s accuracy).
- ALBERT: Lightweight and faster through parameter sharing.
- RoBERTa: Robustly optimized BERT with better performance.
- DeBERTa: Disentangled attention mechanism boosting performance further.
You can often use these variants directly with Hugging Face Transformers.
Limitations of BERT in Text Classification
- Heavy Resource Usage: Requires significant RAM, VRAM.
- Training Time: Fine-tuning can still take hours on large datasets.
- Input Length Limit: Standard BERT limits inputs to 512 tokens.
- Black Box Nature: Understanding why it made certain predictions can be challenging.
Final Thoughts
BERT has fundamentally changed text classification by offering deep contextual understanding with minimal task-specific modifications. Instead of handcrafting features, you now fine-tune a powerful pre-trained model.
Understanding how BERT works for text classification—from input tokenization to extracting [CLS] outputs and training a classification head—empowers you to build robust, state-of-the-art NLP models with relatively little effort.
Whether you are tackling sentiment analysis, intent detection, or document classification, BERT provides a powerful, reliable foundation.
Start experimenting with it, and you’ll quickly see why BERT is considered one of the most important innovations in modern AI!